画像処理AIモデルの
自動構築とその運用
画像処理AIモデルの
自動構築とその運用
本研究では、画像処理のAIモデルを自動生成し、産業への応用をめざす。これらのAIモデルは、画像認識、物体検出、異常検出など、産業応用に不可欠な機能を提供する。さらに、ハードウェアデバイスに合わせてAIモデルを最適化するなど、画像処理AI自動生成に関する研究も含まれる。本研究により、AIの専門家を必要とせずに、中小企業も画像処理AIを導入し、活用できるようになることが期待され、競争力向上に寄与すると考える。
- 所属
- 立命館大学 知的高性能計算研究室
- 代表者
- 孟 林

立命館大学 理工学部 電子情報工学科 教授
孟 林 Meng Lin
立命館大学理工学部准教授。2015年ミネソタ大学情報理工学部客員研究員。300以上の論文を発表、研究分野は計算機アーキテクチャや人工知能など。IEICE、IEE、IPSJ、ACM会員。IEEEシニア会員。
SOCIAL社会実装
多分野の産業ニーズへの適応を
めざす検証実験を展開中
これまで以下の分野で検証実験を行った。 ①ロボットを統合し、AIモデルが食器や箸などを検出し、自動回収する実験をした。 ② AIモデルでの農産物の検査を実施し、リンゴの傷検査などを評価した。 ③ AIモデルを活用して産業の異常検査を行い評価した。また画像処理AIを用いた古代文献の修復も行った。①②についてはハードウェアリソースに合わせてモデルを自動生成した点に独自性があり、③の文献修復は世界でも未開拓な挑戦である。

ORIGINALITY研究の独自性
エンジニア不要でAIモデルを
自動生成できる革新性
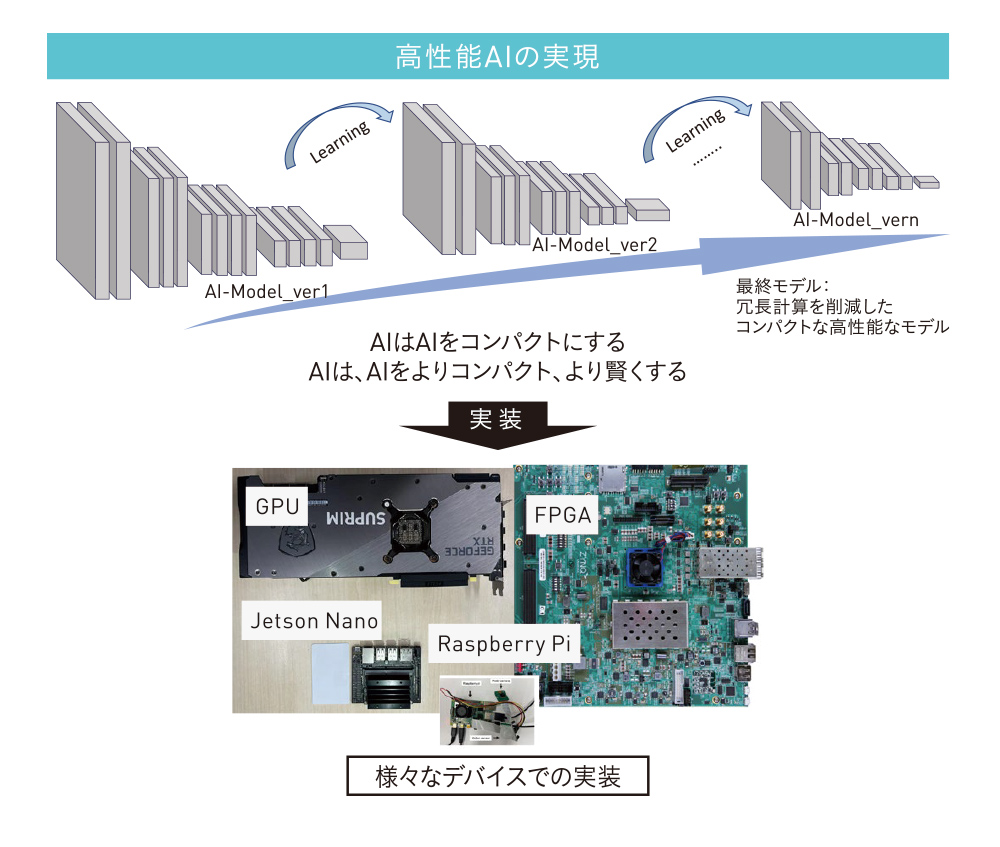
本提案では、必要とするAIの基本パーツから、ユーザーが使用するハードウェアリソースと使用対象に合わせて、AIの画像処理モデルを自動的に構築する。エンジニアを必要としないため、ユーザーが簡便に画像処理AIを導入できる。また自動生成には、処理精度やハードウェアのリソースを考慮した最適化も含まれる。対象とする画像処理も広く、画像分類、物体検出、異常検出などを含んでおり、多彩な産業ニーズに適応可能である。
VISION将来の展望
よりユーザーが使いやすい
統合型AIや対話型AIを構想
現在は物体抽出(お皿や傷のあるリンゴなど)が基本だが、今後は、画像認識、物体検出、異常検出、画像生成など、様々な処理を統合したAIモデルをめざす。またユーザーとの対話が可能なAIモデルへの進化もめざす。これは結果を音声や言葉でユーザーへ提供し、同時にユーザーの指示も音声で受け取り、必要に応じたモデルの再構築を行うもので、例えば異常検出の共有やユーザーからのフィードバックによるモデルの改善が迅速に行える。

image photo

